System Overview
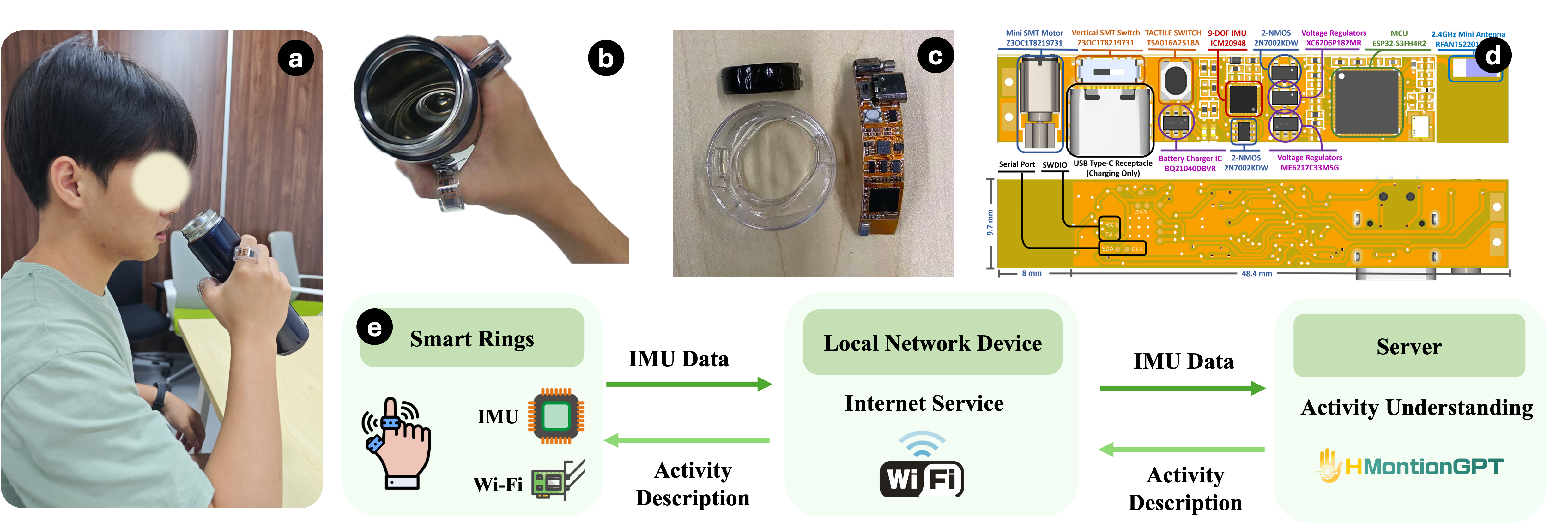
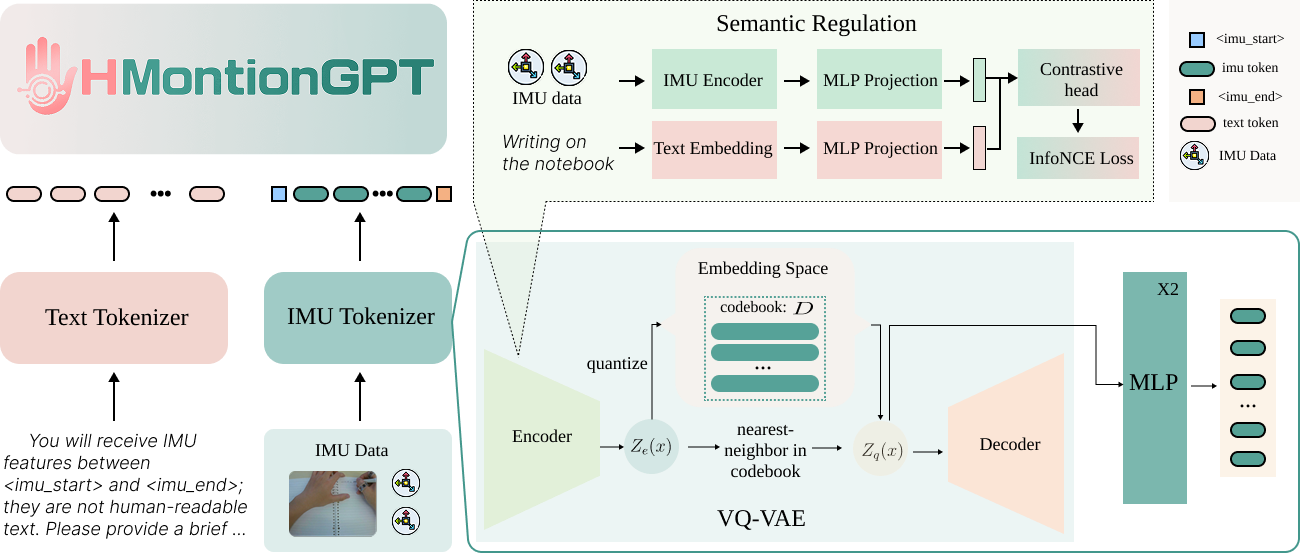
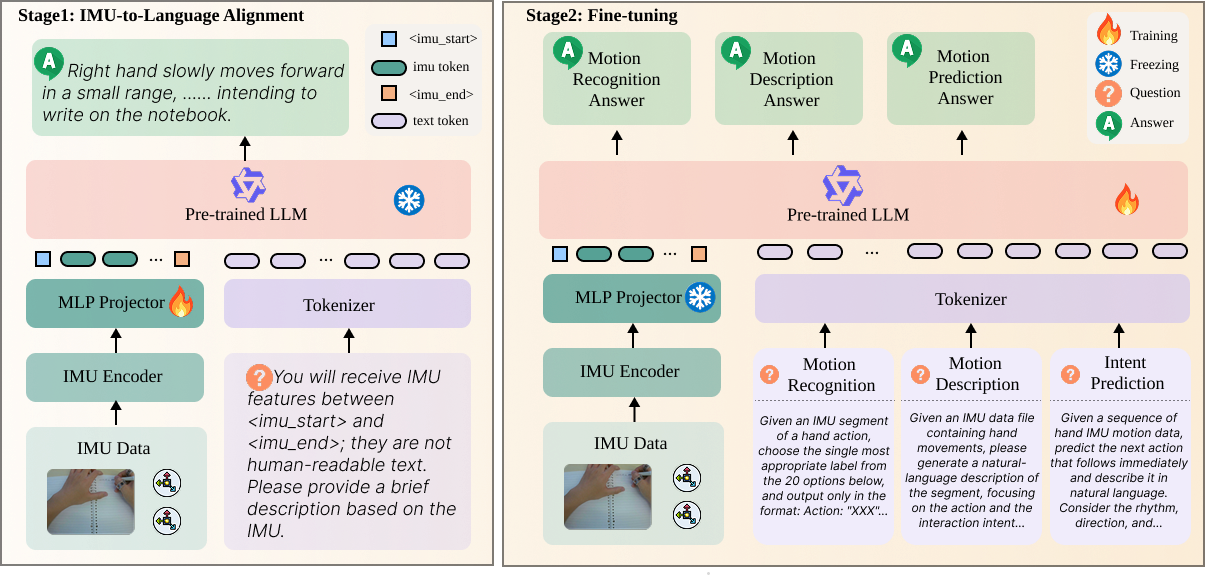
HMotionGPT connects wearable smart rings, backend IMU processing, and language-guided activity understanding in one pipeline. The system is designed for hand-object interaction analysis, turning raw inertial streams into interpretable text outputs that can describe actions, classify activities, and support downstream interaction understanding tasks.